
From Intelligence to Wisdom: Systemic Leverage Points for a Safe AI Future
How systems thinking can support alignment with human values on multiple layers

What if the real “alignment problem” is just as much about aligning us as it is about aligning AI? As we race to align advanced AI systems with human values, we should ask whether our own human systems are aligned with a safe and flourishing future. Artificial intelligence is emerging in a world already facing complex risks — climate change, ecological strain, geopolitical tensions — driven by human institutions that often prioritize short-term gains over long-term thriving.
This article explores AI Safety through a wider lens of systems thinking, with the hope to gain a clearer picture on the root causes of misalignment, and to identify neglected layers of the system that need more of our attention. Whether you’re asking where to put your time and money to steer safe AI, this article might equip you with a fresh perspective on different interventions — from tweaking numbers to changing cultures. My hope is that you will gain a clearer understanding of how your work (or the project you support) fits into the bigger picture, and how combining interventions at multiple levels can shift us from merely building intelligent machines to cultivating wiser outcomes.
Framing the Problem
Let’s begin with a sobering perspective: even without superintelligent AI, our societal “operating system” is already misaligned with long-term well-being. As futurist Daniel Schmachtenberger and ecologist Nate Hagens argue in their discussion “Artificial Intelligence and the Superorganism” modern civilization behaves like a superorganism driven by narrow goals. For example, the global economy is organized around profit and growth as ends in themselves. In their conversation they reflect that “Humans are a social species, and in the modern world we self-organize… around profits. Profits are our goal… And we have outsourced the wisdom and decision-making of this entire system to the market, and the market is blind to the impacts of this growth”. In other words, raw intelligence and competition (to achieve goals like profit) have outpaced wisdom and care for the whole. The result is a system that excels at short-term goal achievement — extracting resources, expanding production — but often at the expense of destabilizing our future. We are drawing down finite resources at millions of times their recovery rate and pushing up against planetary boundaries (six of nine boundaries maintaining Earth’s stability have been crossed, according to the Stockholm Resilience Centre). This misalignment between what we can do and what we should do has been termed a “metacrisis” — a tangle of existential-scale risks created by human cleverness without sufficient wisdom.
Schmachtenberger and Hagens distinguish between intelligence and wisdom as a way to diagnose this problem. Intelligence can be thought of as goal-achieving capability — the power to solve problems and get results. Wisdom, by contrast, is the capacity to choose worthwhile goals and to understand the long-term, holistic consequences of our actions. In their words, wisdom is “related to wholes and wholeness,” whereas intelligence is about “how do I achieve a goal” — often “a narrow thing for a narrow set of agents, bound in time”. Put simply, intelligence is the ability to accomplish what you want; wisdom is knowing what to want in the first place. Our global system has become extremely good at the former (through technology, science, industrial efficiency), but often neglects the latter. Over-emphasis on intelligence — optimizing for narrow metrics like quarterly profits or GDP growth — can lead to Pyrrhic victories. “And I would argue that humanity is in the process of pursuing evolutionary cul-de-sacs, where the things that look like they are forward are forward in a way that does not get to keep forwarding”, as Schmachtenberger puts it. In other words, a society purely focused on short-term intelligence can win the battle but lose the war, creating existential fragility by undermining the very foundations of its survival.
This context is crucial for AI safety. If we plug powerful AI systems (amplified intelligence) into an already misaligned superorganism, we might simply accelerate the drive off the cliff. AI could act as a turbocharger for extraction, consumption, and the pursuit of narrow objectives, unless we ensure the objectives themselves are sound. Thus, aligning AI with human values isn’t enough if those human values are myopic or fragmented. We must also align our societal values and goals with long-term planetary well-being. Schmachtenberger and Hagens call for “progress realism” — a stance between naive techno-optimism and cynical techno-pessimism. Rather than assuming technology automatically saves us or rejecting all technology as evil, progress realism means guiding innovation with wisdom and clear-eyed realism about risks. As Schmachtenberger explains, the key is to define better goals for progress so that making systems more intelligent doesn’t become destructive. The same powerful tech could yield very different outcomes depending on the goals we set for it. If we ensure our goals are broad, inclusive, and long-term — “wide goal definitions” rather than narrow ones — then optimizing with advanced AI can produce true benefits instead of disaster. This is essentially a call to craft a “progress narrative that is post-naive and post-cynical” — one that acknowledges the very real perils of unrestrained technological growth, yet believes we can redirect our course through wiser choices.
Progress realism reframes the AI debate: it’s not about halting progress, nor about blind faith in it, but about steering progress. To do so, we need to widen our focus and consider the broader system in which AI is being developed and deployed. In practical terms, that means thinking about interventions on all levels of the systems, from tweaking numbers, over changing incentives, all the way to shifting paradigms.
Zooming Out to See the System
In 1999, the late systems thinker Donella Meadows published a seminal essay titled “Leverage Points: Places to Intervene in a System.” In it, she presented twelve ways to change a system, from tweaking numerical parameters up to transforming the system’s underlying purpose. These twelve leverage points are often depicted as a hierarchy — “increasing order of effectiveness” from shallow tweaks (like adjusting parameters) to deep shifts (like changing mindsets or goals). Meadows was an eternal optimist about our ability to solve problems, but she urged that we look beyond quick fixes. The key insight of her framework is that some types of interventions have far more impact on system behavior than others. In a Dutch housing development, researchers observed that homes with electricity meters installed in the front hall consumed 30% less electricity than identical homes where the meters were located in the basement. This significant reduction wasn’t due to changes in pricing, technology, or regulations (parameters), but rather a simple alteration in the information flow — a higher leverage point in Donella Meadows’ framework. As one summary puts it, Meadows’ hierarchy encourages practitioners to “not just addressing the symptoms of a problem but engaging with the underlying structures and mindsets that perpetuate it”. In other words, real change often means zooming out to see the whole system and tackling the deeper leverage points, rather than only fine-tuning details.
Importantly, Meadows did not intend the 12 leverage points as a rigid recipe, silver bullet, or a replacement for deep expertise. Rather, they are a tool for reflection and creativity. They help us ask: At what level am I intervening? Could there be a higher-leverage approach to this problem? For those of us concerned with AI safety, this framework can illuminate the landscape of intervention options. We can analyze current AI safety efforts and future strategies in terms of these leverage points: Are we focusing on parameters like model settings and compute limits? Are we creating feedback loops to monitor and correct AI behavior? Are we redesigning the rules and institutions governing AI? Are we ultimately reshaping the intent and paradigm behind how society uses AI? All these layers matter, and thinking in this way ensures we don’t become myopically fixated on just one layer. In the end it also encourages us to think boldly and challenge underlying mindsets, even if we think it might be impossible to shift them at first.
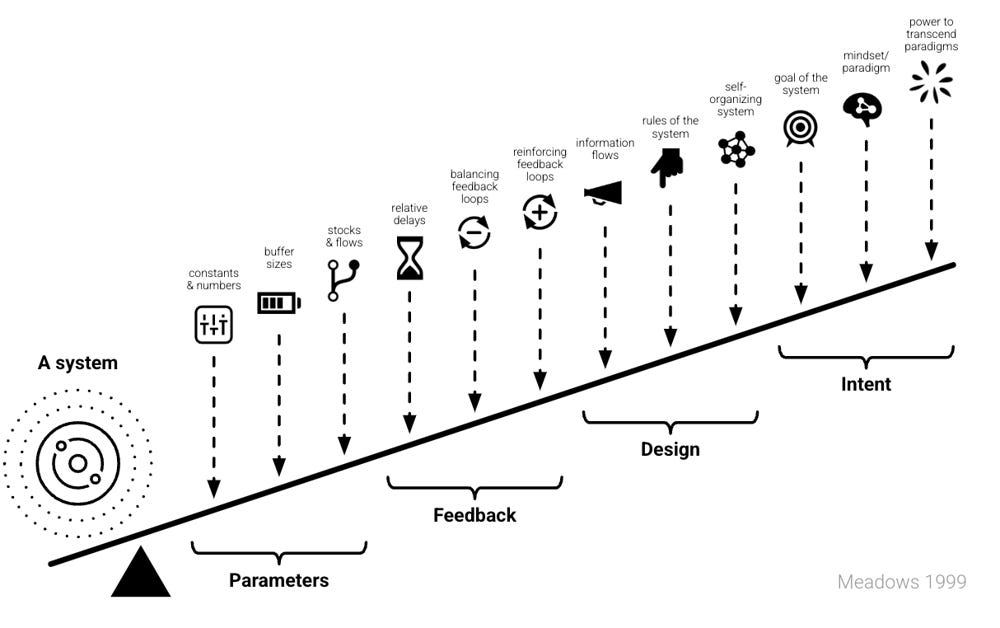
For clarity, we will cluster Meadows’ twelve points into four meta-categories: Parameters, Feedback, Design, and Intent, as illustrated above. The first few leverage points (like constants, buffer sizes, stock-and-flow structures, delays) we group under “Parameters.” The intermediate points involving feedback loops and information flows we label “Feedback.” The next points about system rules and self-organization fall under “Design.” The top leverage points — goals, mindsets, and the power to transcend paradigms — we call “Intent.” This clustering is a simplification (in Meadows’ original list each point is distinct, and some interventions touch multiple points at once). Still, these four levels will help us discuss AI safety interventions in a structured way without losing ourselves in the details. We will examine each level in turn, with examples of AI safety efforts that operate at that level, and discuss how they complement each other. The goal is not to declare any single level as the “right” answer, but to encourage more integrative thinking. Often, effective strategies weave together multiple levels: for instance, a new regulation (Design) might require certain transparency measures (Feedback) or technical standards (Parameters), all motivated by a shift in public values (Intent). By zooming out to see the whole system, we can identify high-leverage points we may be overlooking and that block progress in the larger systems change we want to see.
The Four Levels of Intervention
In the following some selected AI Safety interventions are mapped onto the four different levels, each including level including three intervention points (as indicated by the graphic above). If you are short on time, I recommend you to skim or skip the examples (bullet points). This mapping should not be seen as too rigid, as an intervention might actually act on different systems levels, but it is a good starting point for your own reflection. I invite you to think for yourself to which extent this mapping might only show part of the truth, and ponder where other interventions, that have not been mentioned fall onto the spectrum.
It is important to note that although “Intent” level can lead to deeper and long-lasting systems change, it might also be the one that is most abstract and intangible. Those interventions might take longer to get from action to impact, and they might be more intractable. Thus, usually we gravitate towards lower leverage interventions (“low hanging fruit”), which might give us more progress in the short-term and actually help us to fight catastrophic outcomes. However, to win the long game, we also need to tackle the higher leverage points.
1. Parameters: Tweaking the Dials of AI
At the parameters level, we adjust the immediate, concrete elements of a system — numeric settings, thresholds, resource limits — without changing its deeper structure or goals. In AI safety, many interventions today operate here. They are critical for addressing near-term risks but offer limited systemic change.
Examples include:
Technical alignment tweaks: Researchers develop better training procedures, loss functions, or confidence calibration methods to curb unsafe AI behaviors. Auditing and red-teaming similarly add “buffer stocks” of safety — catching problems before deployment without changing the AI’s core objectives.
Compute and deployment controls: Efforts like compute governance (capping model sizes or training resources) adjust measurable constants to slow risky capability growth, aiming to keep safety progress on pace with AI advances.
Monitoring and evaluation thresholds: Safety benchmarks (e.g., toxicity or bias thresholds) act like setting emission standards — forcing technical fixes before an AI can be released.
Parameter-level interventions are tangible, fast to implement, and necessary. They can immediately reduce acute risks and buy crucial time. Researchers working on adversarial robustness or policymakers advocating for compute limits are contributing at this level.
But parameters are the lowest leverage points. Tweaking dials doesn’t alter the system’s incentives or structure. If competitive pressures reward powerful AI deployment, parameter controls (like compute caps) can be bypassed or gamed. These interventions also need constant maintenance — like endlessly updating filters for new types of harmful outputs.
In short, parameter work is essential for managing immediate threats, but not sufficient for long-term safety. Alone, it risks becoming an endless game of whack-a-mole. True progress requires moving up to feedback, design, and intent — where we can change why the system produces misalignment in the first place.
2. Feedback: Steering AI Systems with Information Loops
Feedback loops and information flows are how systems self-correct — or spiral out of control. Donella Meadows emphasized the importance of both negative feedback (which stabilizes systems) and positive feedback (which can drive runaway growth or collapse). In AI safety, feedback-level interventions aim to ensure we have the right signals, responses, and corrections to guide AI development safely.
Examples include:
Real-time monitoring and oversight: Monitoring systems can watch deployed AI models for dangerous behaviors — like producing prohibited content — and trigger corrective actions: throttling output, alerting operators, or even shutting down a subsystem. These “circuit breakers” prevent runaway errors, much like an engine governor or thermostat. Many AI safety proposals involve building such dynamic guardrails, ensuring AI doesn’t run open-loop without checkpoints.
Human-in-the-loop feedback (alignment feedback): Techniques like Reinforcement Learning from Human Feedback (RLHF) fine-tune AI behavior through human judgments. Humans reward or penalize outputs during training, teaching models to align better with human preferences. In future deployments, user feedback could serve a similar role — allowing AI systems to course-correct in real time rather than blindly optimizing based on outdated goals.
Transparency and reporting requirements: At the ecosystem level, feedback also means ensuring societal visibility. Mandating that labs disclose emergent AI capabilities or incidents is like adding “sensors” for oversight agencies and the public. Without such transparency, risky developments stay hidden until it’s too late. Like early warning systems for pandemics, robust information flows enable faster, smarter collective responses.
Feedback to AI from real-world outcomes: AI systems can also learn by observing the impacts of their actions. If an AI’s supply chain decision harms a stakeholder or reduces efficiency, and this feeds back into its optimization criteria, the system can adapt to avoid similar mistakes. Designing AIs to receive broader, human-aligned feedback from their environment (not just narrow proxy metrics) is an active frontier in AI research.
Why feedback matters: Without timely, meaningful feedback, complex systems drift or crash. Many historical disasters — from ecological collapses to financial crises — stemmed from broken or delayed feedback loops. In AI, the risk isn’t just a “paperclip maximizer” running wild; it’s also subtler dangers, like recommender systems radicalizing users when short-term engagement metrics are the only feedback signal they receive.
Finally, feedback alone can’t fix everything. It keeps a system on course — but if the course itself is wrong, better feedback only ensures we reach the wrong destination more efficiently. To set the right course, we must climb higher: to system design and intent.
3. Design: Shaping the Rules and Structure of the AI Ecosystem
At the design level, we intervene by changing the rules and structures that govern a system — its incentives, constraints, and ability to self-organize. Unlike parameters or feedback, design interventions shape how decisions are made in the first place. In AI, this means reforming the governance, policies, and institutions that define how AI is developed and deployed.
Examples include:
Policy and regulation: Laws like the EU’s proposed AI Act can fundamentally reshape the AI landscape — requiring safety evaluations, banning high-risk applications (e.g., autonomous weapons), and imposing penalties for unsafe deployment. Regulation shifts can cause that AI companies have strong legal and financial reasons to prioritize safety over speed.
Economic and funding incentives: Public and private grants can be directed toward AI alignment, interpretability, and safety research, steering talent and innovation into safer channels. Conversely, reducing perverse incentives — such as engagement-maximizing ad models — would remove pressure toward short-term, harmful AI deployments. How we allocate money and prestige ultimately shapes the kind of AI we get.
Institutions for coordination: AI is a global phenomenon, so we need global structures. Proposals include an International AI Safety Agency or cross-lab safety consortia, modeled after the IAEA for nuclear technology. Coordination institutions help share knowledge, build trust, and reduce the race dynamics that fuel unsafe innovation.
Corporate and organizational design: Within companies, design choices like giving ethics teams veto power, requiring dual-approval systems before deploying powerful models, or committing to safety-centered charters can embed caution into the development process itself. Open science approaches to AI safety research also redesign knowledge flows toward collective benefit.
Why design matters: Design interventions address root causes, not just symptoms. If the “rules of the game” reward caution and cooperation, safety naturally becomes the path of least resistance. Historical parallels — like environmental regulation forcing industries to innovate cleaner processes — show how rules can shift entire systems toward better outcomes.
Thoughtful AI design could make safe practices standard, not exceptional. Examples already moving in this direction include the development of AI ethics standards (e.g., ISO, IEEE) and proposals for compute-sharing alliances to avoid competitive secrecy spirals.
However, design changes are hard. Building new laws or institutions is slow, politically fraught, and prone to gaps if not globally coordinated. Poorly designed rules can create new problems (e.g., superficial compliance without real safety). Moreover, static rules risk becoming outdated as technology evolves — highlighting the need for governance systems that learn and adapt over time.
4. Intent: Goals, Mindsets, and the Wisdom to Transcend
At the deepest level of leverage lies Intent: the system’s goals, the paradigm it operates from, and ultimately, its capacity to transcend paradigms. Intent interventions are about changing why the system exists and what it seeks to achieve. For AI safety, this means asking: What is AI really for? What worldview shapes its development? And might we need to rethink that worldview to safely integrate AI into society?
Key aspects of intent-level intervention:
Shifting system goals: Today, the implicit goal of the global AI ecosystem is to maximize innovation, capabilities, and profit. But what if we consciously reset that goal to maximize human and ecological well-being? Imagine measuring AI progress not by model size or user count, but by how much AI helps solve humanity’s deepest challenges — climate resilience, education, health. Global initiatives like proposing alternatives to GDP (e.g., Genuine Progress Indicator, Gross National Happiness) hint at this broader redefinition.
Changing mindsets and paradigms: Beneath goals lie paradigms — the fundamental beliefs that generate goals. Our dominant paradigm today is techno-economic optimism: faith that more technology and more growth inherently lead to progress. While this mindset fueled historic advances, it also underpins many systemic risks. An alternative, informed by wisdom traditions, would emphasize balance, regeneration, and long-term thinking over growth-at-any-cost. Indigenous governance models, which consider the impact on seven future generations, offer examples. Intent-level interventions here include education, storytelling, and thought leadership that promote wiser narratives — seeing AI not as a race, but as a stewardship challenge requiring responsibility and restraint.
Transcending paradigms: Meadows’ highest leverage point is the capacity to transcend paradigms — to realize that no worldview is absolute and adapt when conditions change. In AI, transcending paradigms could mean questioning the race dynamic itself: What if the goal isn’t to develop the most powerful AI first? Historical precedents exist: the global ban on chemical weapons, for example, shows humanity’s ability to say “we could, but we choose not to.” Transcending paradigms could also involve integrating opposing worldviews: blending scientific rigor with ancient wisdom traditions about our relationship with technology and nature. In the end, this intervention point is about building systems that are adaptive and malleable when it becomes evident that keeping the status quo leads to self-destruction.
Here are some projects that are working on the Intent level:
The Center for Humane Technology works to shift tech industry mindsets.
The Long Now Foundation promotes thinking on 10,000-year time scales.
The Consilience Project seeks to upgrade societal sense-making and foster more holistic governance frameworks.
Bringing it back to AI safety: Schmachtenberger and Hagens emphasize that to align AI with human flourishing, we must first align ourselves with wiser goals and narratives. Wisdom, Schmachtenberger says, involves “the perception of and identification with wholeness” — seeing ourselves as stewards of a larger interconnected system.
Intent change is slow, nonlinear, and often frustrating. You can’t legislate a new worldview overnight. Cultural evolution takes time — through education, discourse, art, and generational turnover. Yet history shows paradigms do change: slavery, the divine right of kings, and unchecked environmental exploitation were once normalized; now they are seen as unethical. If we persist, shifting the paradigm from “technology for domination” to “technology for life” can unlock progress across all other leverage points.
In summary: If you’re drawn to work at the Intent level, you’re helping to build the societal wisdom that will ultimately govern AI’s trajectory. This could mean engaging in ethics, foresight, education, or crafting new cultural narratives. The ultimate alignment challenge is not just ensuring AI aligns with human desires — but ensuring human desires align with the flourishing of all life.
This is the shift from a purely intelligence-driven trajectory to one guided by wisdom. And it may be the most important shift of all.
Conclusion
AI safety is often discussed in technical terms, but as we’ve seen, it spans multiple layers of our socio-technical system. From the nitty-gritty of model parameters to the lofty realm of cultural paradigms, each level of intervention offers opportunities to reduce risk and guide AI towards beneficial outcomes. As you reflect on your own work or charitable choices, it’s worth asking: Where am I focusing, and how does it affect the wider system? For example, a technologist might partner with a policy expert to create an AI safety tool (parameter-level) and find support in regulation (design-level). A nonprofit might combine near-term monitoring programs (feedback-level) with long-term public awareness campaigns (intent-level). By connecting the dots between levels, we amplify our overall impact — interventions reinforce each other rather than working in isolation.
It’s also healthy to zoom out occasionally and examine the big picture of why we do what we do. In the day-to-day grind of research or policy drafting, one can lose sight of the paradigms and mindsets at play. Taking a step back to question, “Are we solving the right problem? How do our immediate goals serve the broader good?” can prevent tunnel vision. This echoes the shift from intelligence to wisdom: intelligence hones in on a goal; wisdom questions the goal and situates it in a larger context.
Ultimately, the challenge of aligning AI with human values may be inseparable from the challenge of aligning human systems with our own values. It calls us to re-imagine progress not as an arms race but as a cooperative endeavor toward a thriving planet. We have an abundance of intelligence at our disposal; it’s time to match it with the courage and foresight of wisdom. In doing so, we can ensure that our most powerful tools, like AI, truly serve the flourishing of life — not just the superorganism’s short-term goals, but the enduring well-being of whole communities and future generations. In the end, the safety of AI may depend on this broader alignment: the alignment of our intelligence with our wisdom, our technology with our humanity.
Please contact me, if you are interested in discussing the application of systems and complexity frameworks to pressing challenges. I am open to support your project as a systems thinking facilitator, bringing more interdisciplinary insight into your journey towards impact.
Note: This article has been created in a human-AI co-authorship, letting human wisdom steer the conceptual direction and editing, and letting AI do the heavy lifting of writing.
Sources and Recommended Readings
Daniel Schmachtenberger & Nate Hagens — “Artificial Intelligence and the Superorganism” (2023)
Donella Meadows — Thinking in Systems: A Primer (2008)
Dario Amodei et al. — “Concrete Problems in AI Safety” (2016)
Long Ouyang et al. (OpenAI) — “Training language models to follow instructions with human feedback” (2022)
Deep Ganguli et al. (Anthropic) — “Red Teaming Language Models to Reduce Harms” (2022)
Oliver Habryka — “A transparency and interpretability tech tree” (2022)
Victoria Krakovna et al. (DeepMind) — “Specification gaming: the flip side of AI ingenuity” (2020)
Hayes et al. — “Computing Power and the Governance of AI” (2024)
Stuart Russell — Human Compatible: AI and the Problem of Control (2019)
Excellent piece, and great to take a step back and offer a new perspective. I agree that Meadows' framework is a very helpful way of framing AI safety interventions. Looking forward to more articles.